
Para volver a ULUM esta temporada, he pensado en hablar de un tema que espero que pueda resultar útil, y de interés, a todo aquel que quiera evitar la desinformación en los medios de comunicación, sobre un tema del que se lleva hablando mucho tiempo y que parece que seguirá en boga: elecciones.
Ahora que somos todos unos expertos votantes, estamos hartos de ver encuestas, y más encuestas, y que estas encuestas coinciden o no con los resultados… A menudo uno se encuentra con las redes sociales acusaciones a que los datos se “cocinan”, o no son correctos. El artículo de hoy será un análisis, en general, a cómo funcionan estas encuestas, y lo más importante, cómo debe interpretarlas usted, querido lector, para no llevarse una desilusión, y tener idea de cuándo le pueden estar tomando el pelo. Intentaré hacerlo lo más sencillo posible, y desde un punto de vista cualitativo. Para el análisis emplearemos las encuestas del CIS, más que nada por la cantidad de datos técnicos de acceso abierto que incluyen en su página web.
Para empezar, hay un concepto fundamental que a los medios se les escapa siempre que dan resultados electorales. Sin excepción, televisión, periódicos, entrevistas… olvidan una cosa muy importante cuando presentan datos de la encuesta: y esto es que la encuesta es una medida experimental, realizada sobre un sistema. ¿Qué quiere decir esto? Que la medida tiene un error, lo cual es fundamental. Lo veremos rápidamente con un ejemplo. Hoy me he pesado en la balanza del baño, y me ha dicho que peso 72.7 kilogramos. La balanza, como se podrá imaginar el lector, solo muestra un decimal. Y por supuesto, suponemos que redondea correctamente. Es decir, si yo peso 72.73 kilos, la balanza dirá 72.7; pero si me peso real es 72.68 kilos, también lo aproximará a 72.7. Es decir, este número lo obtendré siempre que mi peso esté comprendido entre 72.65 y 72.75 (*). Esto, en matemáticas, se escribe de la forma [72.65, 72.75]. Pues mi peso no es exactamente 72.7, sino un número aleatorio en este intervalo, que yo desconozco. Cuando un investigador hace una medida, tiene que admitir que, en efecto, su medida nunca es exacta y se encuentra en un intervalo. La medida está afectada de un error. Fijémonos en el intervalo anterior. Los números que hay difieren de la medida que me da la balanza, 72.7, en sólo 0.05, porque 72.7 – 0.05 = 72.65 y por otro lado 72.7 + 0.05 = 72.75. Por este motivo habitualmente los investigadores escriben los resultados de sus medidas como (72.70±0.05). Esta notación es exactamente igual que el intervalo anterior, pero dice de forma explícita qué he medido yo con mi cacharro, y en cuanta cantidad me estoy equivocando.
En este punto haré una nota importante: normalmente cuando se mide con un aparato se toma como error la última cifra decimal que da. Así, como mi balanza solo da hasta el primer decimal, el error será de 0.1 (en lugar de 0.05), y nuestra medida es 72.7±0.1, lo cual quiere decir que la medida de mi peso real es un número aleatorio dentro del intervalo [72.6, 72.7]. Este es un procedimiento que se hace para asegurarnos de que nuestra medida está seguro en el intervalo que aseguramos que está.
Pues este error es un dato que siempre se olvidan de darnos los medios de comunicación. Las encuestas se basan en un resultado matemático que se llama “teorema del límite central”, que está perfectamente demostrado y que, por supuesto, funciona. Dice cosas como que si yo produzco en mi fábrica diez millones de tornillos al día, para saber cuántos salen defectuosos no tengo que mirarlos uno por uno. Puedo estimar más o menos bien el número de tornillos defectuosos si cojo cien, miro cuántos hay que están mal, y sabiendo eso hago mi estimación. Si hago mi estimación sobre mil tornillos en lugar de sobre cien, mi resultado será más cercano a la realidad. Y si la hago sobre diez mil, más todavía. Con las encuestas pasa igual: no tengo que preguntarle a los cuarenta y pico millones de españoles qué van a votar: puedo coger unos pocos y extrapolar. Pero por supuesto, preste atención: he usado con intención la palabra estimar. El resultado será parecido al real, pero puesto que no he contado todos los tornillos, ni todos los votantes, en algo me estoy equivocando. La magia de las matemáticas es que puedo calcular cuánto me equivoco. Y aquí es donde entramos al meollo del asunto.
El diseño de la encuesta
Ya sabemos que aparte de saber qué hemos medido, tenemos que saber cuánto nos hemos equivocado. A la hora de hacer una encuesta, esto es fundamental. No es lo mismo medir que el 20% de los españoles van a votar al PP a que el 20±50% de españoles vaya a votar al PP. En el primer caso, una cuarta parte de la población lo va a votar. En la segunda, el PP puede que no reciba ningún voto, o puede que incluso le vote más de la mitad del país. Básicamente: una encuesta con ese resultado y no hacer la encuesta es lo mismo. ¡No da apenas información!
El error en las investigaciones sociológicas tiene varias fuentes. Primero, el propio hecho de que las persona a la que preguntas en un futuro pueda cambiar de opinión. Ese error es, en apariencia, el más importante. Sin embargo, es absolutamente análogo a no poder medir más a fondo con una regla o una balanza. Es un error sistemático y que podemos reducir si trabajamos con cuidado. En un laboratorio, usamos balanzas de ultra precisión. En las encuestas, añadimos más y más preguntas. Incluso a veces añadimos la misma pregunta dos veces en distintos puntos de la encuesta, o tal vez una muy muy parecida, preguntamos mucho sobre los mismos temas… Una persona que en la encuesta dice que votará PSOE puede que vote a Podemos. Pero si a esa persona le preguntamos si le interesa otro partido, qué lideres valora más en los partidos, que se identifique del 1 al 10 de izquierdas o de derechas… básicamente, esas preguntas extra permiten afianzar la probabilidad de que se quede el partido que ha elegido en la encuesta o que se cambie a otro, y, en caso de que cambie, saber a quién cambiará. Por supuesto, lo repetiré aquí hasta la saciedad: esto no asegura que pueda decir a quién va a votar esa persona. Por muy buena que sea la encuesta, no es posible obtener resultados individuales. Pero mejorará la estadística y los resultados, reduciendo el error de estos. Aún así hay que tener en cuenta que los errores en las encuestas suelen ser grandes, y reducirlos es muy complicado.
Por otro lado, hay toda una batería de fórmulas matemáticas para estimar a cuánta gente hay que hacerle la encuesta. Es decir, yo digo cuánto error quiero y la fórmula me dice a cuántas personas debo encuestar para tener más o menos ese error (y viceversa, qué error tengo si pregunta a tantas personas).
Una vez tenemos esto en cuenta, ya podemos empezar a preguntar a la gente. Con ello, obtendremos unos resultados. Lo que nosotros tenemos en cuenta como resultado es usualmente la media (aunque a veces otros como la mediana son más significativos, pero eso es otra historia). Este es el que dan todos los medios de comunicación y aparece por todas partes. Pero como deberíamos saber a estas alturas de artículo, tener solo la media es inútil, y necesitamos el error. En este caso, no tenemos un aparato que nos dé una medida, así que hay que calcularlo a partir de los resultados. Para esto se usa a menudo la desviación típica. Conceptualmente es muy sencillo: calculamos cuánto se aleja cada uno de nuestros resultados de la media, y a eso le hacemos la media. Así, el error crecerá si hay muchos resultados que se alejen del valor medio (medidas malas) y será pequeño si todos son muy parecidos (si nuestras medidas son buenas).
¿Por qué demonios le dedicas un artículo a esto?
Parece bastante simplón, ¿verdad? Pues hay un montón de medios de información que no parecen tener claro o bien no están de acuerdo conmigo. Vamos allá. CIS de Abril del 2016, el último que contiene información electoral. Como todos los lectores que siguen un poco el tema sabrán, a los medios les encanta decir quién es el líder más valorado de cada partido, que se puntúa del 1 al 10. Adoran decir que nadie aprueba. En Izquierda Unida que Garzón sea el líder más valorado de momento es motivo de publicidad. Pues yo, me temo, tengo que decirles: nadie sabe quién es el líder más valorado. Veámoslo.
Esto es porque, por ejemplo, Rajoy tiene una media de 2.89, con una desviación estándar de 3.03. Por tanto, la medida de su nota según el CIS es de 2.89±3.03, o sea, un intervalo de [0.00, 5.92]. O sea, sí, señores, puede que el señor Mariano Rajoy haya aprobado en las encuestas. La cosa es, prácticamente hay un intervalo del 0 al 6. Se lo voy a decir fácil. Ni el CIS, ni los medios, tienen ni puñetera idea de cuál es en realidad la nota de Rajoy. Lo que está claro es que no es mayor de 6. Hasta ahí, poco más se puede decir.
Bueno, bueno, si las encuestas del CIS son tan malas, ¿por qué las seguimos haciendo? ¿para qué gastarse el dinero en esa patata de encuesta? ¿por qué no preguntamos a más gente? La cosa es que si esta fuera una encuesta aislada, desde luego, tendríamos un problema: el problema de que no tenemos ni idea de cuál es la nota de Rajoy. La buena noticia es que esta encuesta se hace todos los años, varias veces. Podemos hacer la hipótesis de que la nota que la sociedad le da a Rajoy tarda unos cuantos meses en cambiar, lo que implica que la nota que obtendrá en varios CIS cercanos en el tiempo debería ser la misma (**). En efecto, si tomamos la medida de Rajoy en los últimos cuatro CIS, los números son 2.49, 2.61, 2.89, y 3.08. Según nuestra hipótesis esto es igual que haber realizado el CIS cuatro veces el mismo mes a distintas personas. Son, por tanto, 4 medidas diferentes, pero se ve que el resultado es parecido. Aplicando el análisis estadístico, la nota de Rajoy tras analizar estos últimos CIS es de 2.76±0.27. Aunque mirando datos de varios CIS ahora la nota de Rajoy en concreto parece estar fluctuando, si llega a estbilizarse en el CIS de Julio su nota estará en el intervalo [2.49, 3.03]. Es una apuesta arriesgada usando solo cuatro medidas (y cuatro medidas que probablemente no encajen muy bien en las hipótesis), pero al menos deja claro que es muy improbable que Rajoy suba mucho más allá del 3.
Eso sí, ¿puede Rajoy machacar mis predicciones y sacar la próxima encuesta un 3, un 4, o incluso un 5? La respuesta es sí, porque el error de las encuestas individuales así lo permite (todas tienen una desviación estándar parecida). Por supuesto, ese valor, comparado con el resto de los que hemos obtenido, sería descabellado y se debería simplemente a una fluctuación estadística, un pico de esos raros, un tornillo estropeado entre un millón. Pero es estadística, y esas cosas pasan. Y el problema es que si pasa, los medios lo pondrán como la nota real de Rajoy, sin decir ni mu sobre esto. Luego hay críticas a que los datos se “cocinan” en favor de unos o de otros. Mi respuesta es que estas cosas pasan, el problema es que nadie lo sabe. Es improbable, pero posible.
La conclusión: la nota de una encuesta individual es bastante inútil, por el elevado error de cada barómetro. Sin embargo, si combinamos los resultados de anteriores encuestas, vemos que podemos obtener un resultado más preciso, con un error más pequeño. Sin embargo, no podemos despreciar nunca el hecho de que una medida individual tiene un error y no conocemos exactamente cuál es el valor real de la medida. Otro problema adicional, además, es que sólo se tiene en cuenta la desviación típica, pero no mencionan explícitamente el error debido al tamaño de la muestra, que hay que considerar aparte. Por ejemplo, sobre Rivera hay 2201 valoraciones, sobre Garzón 1610, y con los partidos autonómicos llegan a ridículos 67 valoraciones (Íñigo Alli) o 55 (Onintza Enbeita) lo cual afecta de una forma peligrosa a la estadística. Con la encuesta total (unas 2200 personas) aseguran que hay un 2% de error, de modo que, ¿cuál es el error asociado a las valoraciones de Alli o Enbeita? Parece que en este caso el error es mucho, mucho más grande que la desviación estándar. De modo que aunque a lo largo del tiempo las valoraciones estén aproximadamente en torno a un valor medio, no podemos comparar entre líderes alegremente en cada encuesta invidual.
Analicemos por tanto la nota de los cuatro líderes de los partidos más destacados en el último CIS (Abril 2016). Estas son: Rajoy, (2.89±3.03); Iglesias, (3.16±2.90); Rivera, (3.99±2.71); Sánchez, (3.74±2.68). Los intervalos posibles de las notas los representamos en la siguiente imagen. Como podéis observar, tenemos un problema: ¡es imposible saber quién ha sacado más nota!

Muy bien, esto ocurre si hacemos caso solo a esta última encuesta. Usando datos cruzados de los cuatro últimos CIS podemos tratar de reducir el error. En los CIS DE 2015 no aparecen Iglesias ni Rivera, de modo que nos quedamos con dos contendientes: Rajoy, (2.76±0.27) y Sánchez (3.73±0.10). Aquí ya las líneas quedan claramente separadas y podemos decir, con seguridad, que Sánchez tiene una nota mayor que la de Rajoy, intervalo de incertidumbre incluido (***). Eso sí, no hay que olvidar el 2% de error que proviene del tamaño de la muestra… que nuevamente invalidaría este resultado.
Quiero hacer un comentario más a la hora de usar los datos de varios CIS. Para poder hacer esto suponemos que la nota del líder político se mantiene más o menos constante en un periodo suficientemente corto de tiempo. Esto, por supuesto, implica que no podemos coger una gran cantidad de barómetros. Nuevamente quiere decir que usamos una estadística con 4 ó 5 valores. Para una medida de laboratorio esto está bien, porque el error de nuestro aparato es pequeño. Sin embargo, el error de nuestro aparato sociólogico, que viene dado por el error de cada encuesta individual, es muy grande. Esto quiere decir que si yo hiciera 1000 test del CIS el mismo mes, tendría muchos valores como los que he mostrado antes para Rajoy, relativamente parecidos. Sin embargo, habrá algunas fluctuaciones bastante grandes, porque así lo indica el error. Esto tiende a subir la desviación típica, que debe ser bastante más grande de la que he estimado con 4 datos.
Así que, como resumen de este apartado: las encuestas individuales tienen errores demasiado grandes; podríamos usar los resultados de varios CIS para corregirlo, pero no tenemos datos suficientes como para arreglarlo del todo. La única solución es repetir más veces el test del CIS el mismo mes, las suficientes como para hacer una buena estadística, y promediar sobre estos valores. Preguntar a más gente, será de poca ayuda para las encuestas individuales, porque lo que muestran las encuestas es la que las respuestas obtenidas son muy dispares (desviación típica alta), de modo que la desviación típica no se va a reducir mucho, luego la mayor fuente de error de estas notas no se va a reducir. Aumentar la muestra, eso sí, reducirá el error asociado a preguntar a poca gente, que hay que añadirlo (y no lo hemos hecho) y en ocasiones es el que da más problemas para tratar con la medida real.
Cocinando la intención de voto
Finalmente, tras unos aperitivos, nos queda el plato fuerte, una de las cosas de las que más se queja la gente. ¿Qué pasa con la intención de voto? ¿Qué es esa famosa cocina del CIS?
Para empezar, nuevamente hablamos del error. Si nos metemos en la ficha técnica del cuestionario del CIS de Abril de 2016, advierte que para las condiciones estudiadas el error es del ±2%. Así, para empezar, si el CIS hace una predicción de que Ciudadanos obtendrá un 14% de los votos, en realidad lo que quiere decir es que obtendrá un (14±2)%, es decir, un resultado en el intervalo [12, 16], que es bastante amplio, hablando de una estimación electoral. Por otro lado, y esto es importante, se trabaja al 95% de confianza. Es decir, ellos aseguran que el resultado de Ciudadanos estará dentro de [12,16] con un 95% de probabilidades. Puede que el resultado real se salga de ese intervalo, y eso pasará con un 5% de probabilidad. Aunque un 95% parece bastante, en realidad no es demasiado: en ciencias exactas habitualmente se trabaja al 99% de confianza. Y como podréis ver, la diferencia se nota entre los resultados y las encuestas.
Por otro lado, tenemos que diferenciar los dos resultados principales electorales que nos devuelve una encuesta como esta. La intención directa de voto es el resultado en crudo de preguntar al votante, “¿A quién vas a votar estas elecciones?” y registrarlo. Este resultado tiene errores por dos lados. Por un lado, no estamos preguntando a toda España a quién va a votar, solo a una muestra, lo que ya tiene de por sí un error asociado (según el CIS, recordemos, del 2%). Pero es que además, los encuestados pueden cambiar de opinión entre la encuesta y las elecciones. Aunque preguntáramos a toda España a quién va a votar en las elecciones en Abril, en Junio los resultados podría ser distintos. Y si solo estamos preguntando a una muestra, apaga y vámonos. Ya tenemos bastante error con lo que nos dan las matemáticas, no queremos más, ¿qué hacemos para reducirlo?
Pues calentar un poco el resultado crudo. Para ello, como hemos dicho antes, se requiere una serie de preguntas de control para hacernos una idea del perfil ideólogico del votante. La idea es añadir una gran cantidad de preguntas que nos permitan tener un modelo sobre el test que sea capaz de predecir cuál es la diferencia entre los datos de la encuesta y los datos reales. Como el lector se puede imaginar, esto no es sencillo en absoluto, y más en un escenario de elecciones con tantas posibilidades.
Por ello, nos queda añadirle unas especias a este resultado al que hemos aplicado un modelo matemático. Y se basa en coger, simple y llanamente, los resultados de elecciones anteriores. ¿Cuál fue nuestra predicción en 2011? ¿Y cuál fue el resultado? Comparando los resultados históricos de las elecciones y añadiéndolos al algoritmo matemático corregimos lo que ya hemos controlado con las preguntas de control. Aplica esto a todas las elecciones de los últimos años y haz una análisis cruzado para predecir en qué me voy a equivocar este año. Aún así, esto no deja de ser una estimación: al hacerlo, suponemos que estas elecciones serán iguales que las de 2011, que mi análisis se ha equivocado igual que en el de 2011… y esto, por supuesto, no es verdad. Pero de todas formas con un análisis de datos cuidadoso se pueden mejorar los resultados de la intención directa de voto.
¿Qué ocurre con los partidos emergentes y las encuestas? Sencillamente, cuando se realiza un análisis de datos de años anteriores, estos partidos no existen. No hay manera de tratar con ellos. Eso hace que los datos sobre partidos emergentes sean más complicados de tratar y que, por supuesto, hacer predicciones sea más complicado, lo que explica en parte que a veces las encuestas tengan resultados “raros” trabajando con estos partidos, ya que el algoritmo pierde parte de su eficacia.
De hecho, cuando el CIS pregunta intención de voto hay un campo de “no sé a quién votar”, que de hecho contiene a buena parte de los encuestados. Hay un 15.9% de indecisos en Abril de 2016, según el CIS. Eso es mucho, comparando por ejemplo con el 17.3% que tiene claro que votará al PP o el 15.3% que votará al PSOE. El modelo de estimación asignará este porcentaje entre los distintos partidos, y puede que haga algún ligero cambio en aquellos que votarán “seguro” a un partido.
Una solución aplicable es emplear varios modelos de estimación. Puede que el modelo de estimación actual del CIS no se ajuste bien a la situación política actual; ellos mismos advierten que emplean un único modelo para estimar, y que existen más. Cada modelo de estimación tiene en cuenta variables distintas y lleva a estimaciones distintas (¡puede que incluso muy distintas!). Pero aún así, vamos a ver que los resultados no son tan descabellados como parecen a veces.
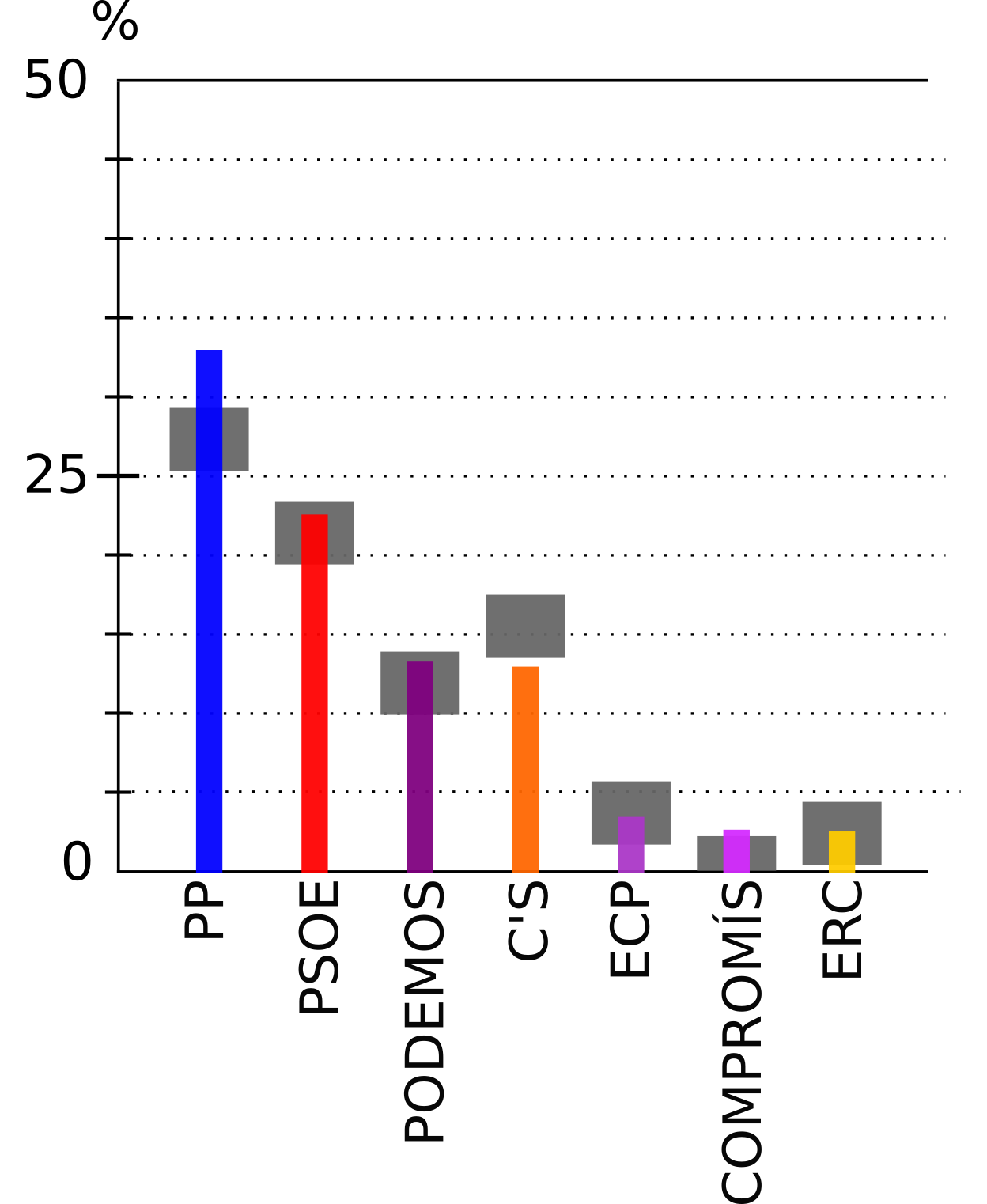
La gráfica anterior es muy interesante. Aunque no están todos los datos, se observa que el CIS acierta de pleno en la mayor parte de las ocasiones. Los medios o los partidos se fijan en el hecho de que el resultado ha sido mayor que lo que viene en la encuesta, sin tener en cuenta el error. Es decir, por ejemplo en el caso de Podemos, los medios dirán que supera las expectativa de las encuestas, al obtener un 13% frente al 12% que le asigna el CIS. En realidad, esto no es así, porque el CIS la predicción que realiza no es que se obtendrá un 12%, sino que el resultado está entre el 10% y el 14%, que es lo que muestra el cuadrado gris de la gráfica. Esto es un acierto completo para la encuesta.
Si realizamos la comparativa de este CIS con los resultados reales, vemos que han acertado para 10 de 13 partidos presentados (****), lo que hace un 77% de aciertos. Esto es más bajo que el 95% de confianza prometido. Hay varias causas posibles para esto: un problema en el modelo de estimación o el hecho de que el barómetro se realizó dos meses antes de las elecciones. Estas causas, lo que hacen es simplemente aumentar la incertidumbre sobre la medida, con lo que los errores son en realidad algo mayores del 2% que aseguran en el CIS. Por tanto, es posible que sean lo suficientemente grandes como para que C’s y Compromís, que están cerquita del cuadradito gris sí entren dentro de la predicción (en Abril) y tengamos 12/13 = 92% de aciertos.
Por desgracia esto último es demasiado aventurar, ya que el CIS no dice cuál es la desviación estándar de la intención de voto directa, ni nos dice cuáles son las fuentes causantes del 2% de error estimado en los porcentajes, ni si ese error incluye el hecho de que entre Abril y Junio algunas personas cambiarán de opinión.
En todo caso, como conclusión, me gustaría defender un poquito a la gente que hace encuestas. Una encuesta bien hecha, correctamente realizada, tiene unos resultados, que hacen unas predicciones limitadas por el diseño de la encuesta y la estadística pertinente. Saber cuáles son las fuentes de error en la encuesta y tratar de limitarlas lo máximo posible consigue que los resultados sean precisos y fiables. Por otro lado, la magnitud de los errores en las encuestas explica malentendidos del tipo “¿Cómo es posible que la encuesta dijera tal y el resultado real sea tan distinto?”, ya que un error grande hace que ese resultado tan extravagante caiga dentro de las posibilidades (aunque nadie nos lo diga). Y por último, es posible comprobar que en las encuestas como el CIS existen limitaciones y errores no controlados que limitan la precisión del barómetro.
Espero que el análisis aclare un poco cómo se deben interpretar correctamente los datos de las encuestas y por qué a veces nos extrañan tanto. Y ojalá que algún día los medios aprendan a dar un poco mejor esta clase de información, que es útil al ciudadano… cuando se hace correctamente.
Notas técnicas
(*) El que sea atento se dará cuenta rápidamente de que en realidad no llegará nunca al 72.75, sino que se queda en el 72.499999… ya que si no estaríamos subiendo al 72.8, y por tanto el intervalo realmente es el [72.65, 72.5[. Lo he escrito así por hacer más fácil la lectura y no extenderme explicando intervalos, que no es relevante para el artículo porque una vez introducida la notación con un ± todos los intervalos ya son cerrados.
(**) Esta hipótesis puede parecer algo aventurada, pero se justifica viendo los datos de los CIS. Al hacerlo, encontramos meses donde la nota de los políticos está relativamente estable en torno a un valor, hay un par de meses donde fluctúa, y luego pasa a estar estable durante otros cuantos valores. Esto implica que en efecto la nota de un político no cambia mucho durante cierto tiempo, y por tanto todos esos CIS son medidas de la misma nota, lo que es equivalente a hacer el mismo CIS varias veces cada mes y obtener una serie de medidas. En el caso de Rajoy, ahora mismo está sufriendo algún cambio, pero hay momentos en los que se mantiene bastante constante.
(***) Alguno que sepa del tema se me puede quejar aquí. Si considero estrictamente que las medidas que me da cada CIS son como del laboratorio, la desviación estándar sería equivalente al error que da la balanza al principio del texto. Esto es, la medida con error sería (promedio de las medidas) ± (promedio de los errores) y no (promedio de las medidas) ± (desviación típica de las medidas). Y los errores son más o menos igual de grandes en cada CIS, luego no arreglamos nada. Yo estoy suponiendo que tengo un conjunto de datos que corresponden todos a la misma medida y aún no tienen asignados un error, ya que es extraño que en una serie de 50 o 100 datos que está bastante en torno a un valor (por ejemplo un 2%) tenga un error del 3%. Sin embargo, por ese mismo motivo estoy subestimando bastante el error de este conjunto de datos, al tener solo 4 datos, y no 50 o 100, que incluirían bastantes fluctuaciones estadísticas (provenientes del gran error de cada encuesta individual) y que podría subir bastante la desviación típica de los datos, aunque probablemente lográsemos reducirla respecto a la de de un CIS individual.
(****) Teniendo en cuenta que el CIS se refiere a “Otros Partidos” como los que han sacado menos votos que PACMA, incluyendo a este partido, y tomando este dato como otro partido cualquiera (ya que el CIS estima el total de estos votos). Para los demás se ha ido comparando el resultado numérico que da el barómetro respecto al que dan los resultados de las elecciones.