
Hoy vamos a hablar un poco de la llamada “ciencia de redes complejas”, un campo que en los últimos años ha crecido rápidamente y que empieza a dar unos resultados bastante interesantes. Para ilustrar qué entendemos por redes, y qué clase de cosas se pueden hacer con ellas, de manera sencilla, vamos a utilizar como ejemplo un proyecto en el que algunos de mis compañeros de clase y yo hemos estado trabajando: el análisis de las relaciones de personajes en algunas novelas.
La idea de este pequeño proyecto surgió cuando nos pidieron contribuir con un póster, sobre nuestro trabajo del máster, en el centro en el que estudiamos, el Instituto de Física Interdisciplinar y Sistemas Complejos (IFISC), un centro de investigación del CSIC. El póster se hizo para la Poster Party, un evento en el que los investigadores muestran su trabajo, de forma distendida y a través de pósters, a otros compañeros. Aunque no esperábamos grandes cosas, no solo resultó el más votado de la fiesta, sino que también hemos sido mencionados en algunos medios digitales, así como en la radio local de Baleares. Como a todo el mundo le ha divertido bastante esta idea del análisis de personajes de novelas, y ya que he participado directamente en el proyecto, creo que es una buena excusa para introducir el concepto de red y ver un poco el potencial que tienen estas estructuras, así como de explicar con más detalle qué es lo que hemos hecho.
Convirtiendo libros en redes
Lo primero que tenemos que hacer, por supuesto, es decir qué es una red. Es tan sencillo como coger unos “nodos” y unirlos a través de unos “enlaces”. Un ejemplo muy ilustrativo es el de los aeropuertos. Podemos considerar que cada aeropuerto es un nodo, y dos aeropuertos conectados por un vuelo tienen un enlace. Por ejemplo, entre Granada y Palma de Mallorca hay vuelos directos, así que son dos nodos conectados. Cogiendo muchos aeropuertos y uniéndolos entre ellos tenemos una red, de una forma bastante intuitiva.
En el caso de nuestras novelas, cada personaje es un nodo distinto. Los personajes que tienen relación entre sí están unidos por enlaces. En el caso de Harry Potter, por ejemplo, Harry y Ron están relacionados, por tanto son dos nodos unidos por un enlace. A su vez, Ron está unido a otros, como Hermione o Ginny. Sin embargo, como podréis imaginar, no todas las conexiones son igual de importantes. Harry y Ron están muy relacionados, mientras que Harry y Luna Lovegood no están tan unidos. Es necesario algo más, que identifique la fuerza del enlace. Esto se hace a través de un peso, un número asociado a cada enlace. A mayor peso, más relación entre ambos.
¿Qué es lo que hicimos nosotros para crear una red a partir de la novela? Basándonos en una investigación anterior que hacía un análisis similar con la novela Juego de Tronos, procesamos el texto de la novela con un programa de ordenador, así como una lista de nombres de personajes que aparecen en el libro. Cuando el programa encuentra un nombre de la lista, cuenta 15 palabras hacia adelante, en busca de otro nombre de la lista. Si encuentra otro nombre, crea un enlace entre los dos personajes mencionados, o bien aumenta el peso del enlace. Por si no ha quedado demasiado claro, ilustraré el método con un fragmento de la novela Dune:
Men moved behind Jessica, dropping a curtain across the opening. A single glowglobe was lighted overhead far back in the cave. Its yellow glow picked out an inflowing of human figures. Jessica heard the rustling of the robes.
Chani took a step away as though pulled by the light.
Jessica bent close to Paul’s ear, speaking in the family code: «Follow their lead; do as they do. It will be a simple ceremony to placate the shade of Jamis.»
Lo primero que se hace es eliminar todo signo de puntuación y cambiarlo por espacios, para evitar que estos signos interfieran con nuestra detección de nombres. Así, Paul’s queda como Paul s, que el ordenador puede separar más fácilmente. Después, el código va buscando los nombres, que he señalado en negrita, y cuenta 15 palabras hacia delante. Así, en la primera ocurrencia de Jessica, vemos que está relacionada con Chani, puesto que están separadas solo por 7 palabras, así que se crea un enlace entre ellas. Cuando el ordenador procesa luego a Chani, detecta nuevamente a Jessica más adelante, reforzando el enlace. Jessica encontrará finalmente a Paul, creando un nuevo enlace. Paúl y Jamis están demasiado lejos como para estar relacionados en este fragmento.
Por supuesto, este método tiene algunos problemas. Por ejemplo, si en vez de Jessica el libro usa “la madre de Paul” para referirse a ella, no solo no estoy contando a Jessica sino que puedo estar incluyendo enlaces potencialmente falsos entre Paul y otro personaje. Hay algunas soluciones para esto, pero en este caso consideramos que los libros son lo suficientemente largos, y los personajes nombrados tantas ocasiones que estos casos no van a afectar demasiado a nuestro análisis. Como veremos, esta hipótesis, aunque algo arriesgada, funciona bastante bien.
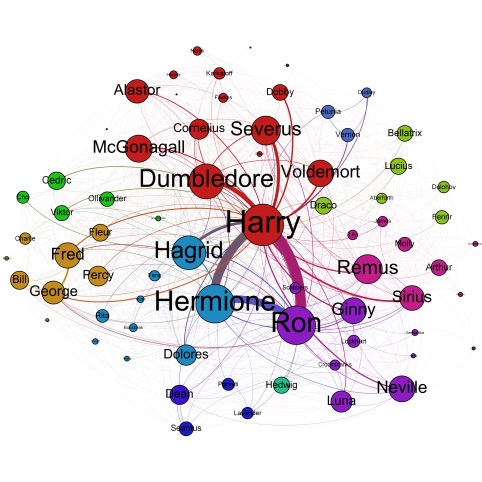
Así encontramos redes como esta, realizada para las siete novelas de la saga de Harry Potter:
Analizando la red
Ahora que tenemos una red, el siguiente paso es analizar algunas de sus características. En el estudio teórico de las redes hay muchas cosas que nos pueden interesar, dependiendo de qué queramos buscar. Por ejemplo, en una red de aeropuertos, es muy importante la longitud de camino: es decir, dados dos aeropuertos cualquiera de la red, cuántos vuelos como mínimo tengo que hacer para ir de uno a otro. Por supuesto, no todos los aeropuertos están separados por la misma distancia. Por tanto, normalmente calculamos la media entre estas medidas, o en ocasiones el diámetro de la red (que es la máxima distancia entre dos aeropuertos).
En nuestro caso, estamos especialmente interesados en las preguntas:
- ¿Se parecen las relaciones entre los personajes de las novelas a las relaciones reales entre personas?
- ¿Podemos agrupar a los personajes en grupitos, comunidades, como los “buenos” y los “malos”, a partir de la información de la red?
- ¿Es posible establecer quién es el protagonista o qué papel juega cierto personaje en la novela?
Para responder a la primera, primero tenemos que saber cómo es una red real, una red en la que los nodos son personas reales y los enlaces son amistades entre ellas. Esta clase de red es muy particular; no voy a hablar de las diferencias entre los distintos tipos de redes aquí, pero quiero resaltar que es una red que tiene un gran agrupamiento de los nodos, y sin embargo a la vez la distancia media entre dos nodos cualquiera es muy baja. Aunque no parezca una propiedad muy impresionante, es algo que no ocurre en redes realizadas al azar o en redes totalmente regulares. El dato sorprendente es que la distancia media entre dos personas cualquier en el mundo es de solo 6 personas. Cualquier otra persona en cualquier rincón del mundo está separada de ti, de media, en 6 pasos, que es una cantidad ridícula teniendo en cuenta que somos miles de millones. Esto se ha demostrado ya en varias ocasiones, usando por ejemplo Facebook o conversaciones en Messenger. El típico refrán de “el mundo es un pañuelo” es literalmente cierto. Las redes en que tienen esta clase de conexión se conocen como mundo pequeño, y muchas de las que se observan, en la sociedad o en la naturaleza, tienen esta característica. Además, la forma en la que los nodos se conectan no es una cualquiera, sino en una distribución conocida como ley de potencia. Nuestras novelas también se organizan como leyes de potencias, y también tienen esta característica de mundo pequeño, con lo que podemos decir que son bastante similares a las redes reales. La red más grande que hemos procesado, de El Señor de los Anillos, tiene cerca de 350 personajes. A pesar de ello, la distancia media entre dos cualesquiera, cogidos al azar, es de apenas 2 personajes.
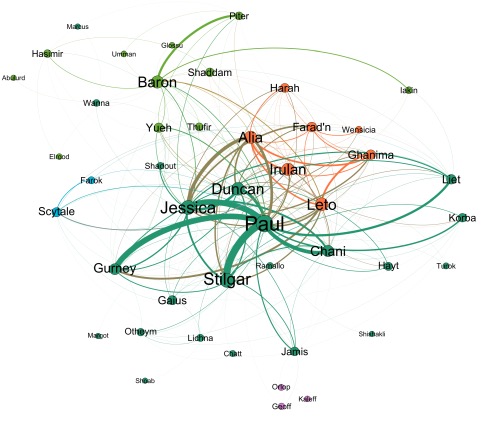
La segunda pregunta es algo más complicada. Existen algoritmos para detectar comunidades, pero el problema es definir qué es para nosotros una comunidad. Intuitivamente todos tenemos la idea, pero cuando se trata de cuantificar en la red, no es tan sencillo. Nosotros utilizamos un algoritmo (que por cierto, no inventamos nosotros, como afirman algunos medios) que trata de maximizar una cantidad llamada modularidad. Cuando esta se maximiza, cada comunidad resultante tiene más enlaces dentro de su comunidad que fuera de ella. Aunque ni la definición de comunidad ni el algoritmo son perfectos, los resultados son bastante buenos. Para nuestras redes, cada comunidad está identificada con un color diferente. Si observamos las imágenes, en el caso de El Señor de los Anillos, los nobles de Rohan y Gondor aparecen en una sola comunidad, los hobbits de la Comarca en otra, y los enanos y elfos tienen cada uno la suya. En Harry Potter, los profesores de Hogwarts tienen su comunidad, al igual que los mortífagos. Como dato divertido, la familia adoptiva de Harry tiene su propia comunidad. Por último, en Dune, la gente del desierto tiene una comunidad para ellos, la familia de Paul tiene otra, los Harkonnen otra, y los descendientes de Paul y otros personajes de palacio (que cobran importancia en la tercera novela) tienen una distinta.
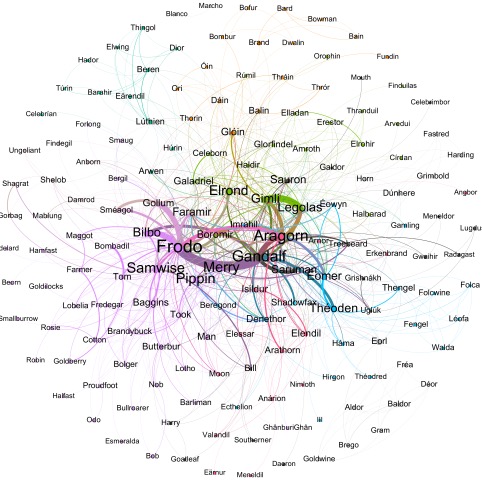
Finalmente, tratamos de buscar el personaje más importante. Para ello, lo que hacemos es obtener un parámetro denominado centralidad. Cuando viajamos de un nodo a otro de la red, hay personajes por los que pasamos muy a menudo. Por ejemplo, para ir de Bellatrix a Petunia por el camino más corto, es necesario pasar por Harry. Para ir de George a Cho solo tenemos que pasar por Fred y Fleur, y no necesitamos para nada a Harry. La centralidad nos dice cuántas veces un personaje hace de puente al ir cogiendo parejas. La idea es que si un nodo es muy importante en la red, una gran cantidad de parejas pasarán obligatoriamente por él. En el caso de las novelas, además, es claro que el protagonista realiza exactamente esta función de puente entre personajes. Por ello nuestra hipótesis fue que los protagonistas y los personajes principales debían de tener una centralidad más alta. Si puntuamos el parámetro del 0 al 100, resulta que en El Señor de los Anillos el valor más alto lo tiene Frodo, con 18. En Harry Potter, este personaje es el protagonista, con 26. Finalmente, en Dune, Paul Atreides gana con un 32.
Esto es interesante, porque el cálculo de la centralidad no sólo nos dice qué personaje es el más importante de la novela, sino cuánto gira la trama alrededor del personaje principal. En El Señor de Los Anillos, en el que el relato se encuentra fragmentado, la centralidad del protagonista es baja, porque la narrativa divide el peso de la trama entre varios personajes. En Harry Potter, Ron y Hermione tienen también una centralidad parecida a la de Harry, mostrando que el peso del relato cae fundamentalmente sobre estos personajes. Por otro lado, las tres primeras novelas de Dune cuentan la ascensión de Paul Atreides a Emperador de la Galaxia y toda la trama de su palacio, de modo que finalmente toda la novela gira, de un modo u otro en torno a este personaje -dando la centralidad más alta de todos los análisis.
Y todo esto, ¿para qué sirve?
Dejando aparte el interés literario que esto pudiera tener para hacer un análisis crítico de cómo se construyen los personajes de una novela, lo cierto es que estudiar las características de una red y cómo se unen los nodos entre ellos es fundamental en muchas aplicaciones. Para no alargarme mucho más, voy a destacar dos de mis favoritas.
La primera la usaré como ejemplo intuitivo: la red social de Facebook, en la que cada persona es un nodo, y dos personas se encuentran conectadas si son amigos. Podemos, en esta red, hacer un análisis de la comunidades que aparecen, para así agrupar a las personas que se encuentren relacionadas. Ahora, llamemos Pedro y Laura a dos personas que no son amigas, pero nuestro algoritmo ha determinado que están en la misma comunidad. Entonces, podremos ponerle un mensajito a Pedro, diciendo que tal vez le interese conocer a Laura. Esta es una posible manera de determinar esas “personas que quizás conozcas” o “tal vez te interese seguir esta cuenta”. Aunque en realidad el proceso es algo más complicado, esta es una de las ideas fundamentales del algoritmo.
Otra aplicación se encuentra todavía en fase de investigación, y es el pronóstico de avance de epidemias. Es posible emplear redes de movilidad (aeropuertos, carreteras, rutas comerciales…) junto con datos reales de cómo viajan las personas para simular cómo se propagan las epidemias. Los resultados son más que prometedores, y pueden ser de ayuda para prevenir pandemias. Una idea sencilla para detenerlas es buscar nodos con alta centralidad, y eliminarlos de la red (por ejemplo, suspensión de todos los vuelos de cierto aeropuerto, o poner tal ciudad en cuarentena). Como hemos explicado antes, los nodos con alta centralidad hacen de puente entre muchos sitios. Cuando eliminamos varios nodos de este tipo, conseguimos que sea mucho más difícil moverse de una punta a otra de nuestra red, impidiendo el avance de la epidemia. Y al mismo tiempo, solo tenemos que paralizar aeropuertos o ciudades concretas, sin necesidad de poner en cuarentena áreas grandes. Un ejemplo contrario lo encontramos en Internet o en la red eléctrica: nos interesa evitar que caigan nodos importantes, para impedir apagones masivos que afecten a un gran número de personas.
En todo caso, conocer bien cuáles son las características de la red (si es de mundo pequeño, si tiene nodos con centralidad alta, si está muy distribuida en comunidades…) tiene una gran cantidad de aplicaciones prácticas, y muy útiles para nuestro día a día. Aunque nuestro proyecto sobre literatura sea esencialmente ilustrativo, es una buena forma de ver todo lo que esta rama puede aportarnos.
Finalmente, me gustaría mandar desde aquí un saludo a mis compañeros de máster, por las horas de diversión durante la realización del póster. Los otros autores de esta pequeña investigación son Ana Alonso, Joan Losa, Luca Marconi, Álex Molas, Alejandro Morán, Gianmarco G. Pisano, Joan Pont, Patrick Sánchez, Miguel A. Trigo y Eduardo Varela.
¡Nos vemos en la próxima!