
Artículo 1: Lo que el cerebro de silicio le ensena al cerebro biológico
Artículo 2: Así sentimos el movimiento
Artículo 3: Y el cerebro de silicio habló
Cuando comencé a escribir la primera entrada de esta trilogía, tenía algo en mente completamente distinto a lo que ha terminado siendo. La idea original era explicar una serie de conceptos y concluir con un nexo de unión entre el cerebro humano y los algoritmos informáticos. Tras varios artículos y vueltas varias, ahora, por fin, intentaré explicar esa conexión entre los cerebros biológicos y los artificiales.
La historia comienza con el programa Apolo de la NASA (1960) y su necesidad de que una nave espacial, a menudo sin humanos que la dirija, “conozca” su posición y pueda autocorregir su trayectoria si hay algún problema.
Por ejemplo, pongamos que tenemos un robot en Marte que se dedica a recoger basura, llamémosle Wally (sin la -e, que nos demandan por plagio). Tiene un GPS como el de nuestros móviles que le indica su posición actual (Posición t0), y quiere desplazarse 5 metros para recoger una caquita metálica, por lo que envía una Orden a sus ruedas para que se desplacen hasta la posición final (Posición t1). Pero, ¿cómo puede conocer Wally su posición actual?

Por una parte, puede utilizar la Posición t1 que le indica el GPS, su sensor, pero sabemos que un GPS no da una medida totalmente exacta, sino que hay un error de varios metros. Por lo que no podemos saber exactamente ni la Posición t0 ni la nueva Posición t1. Lo que nos indica es un área aproximada, de unos 3 metros, en cada posición.
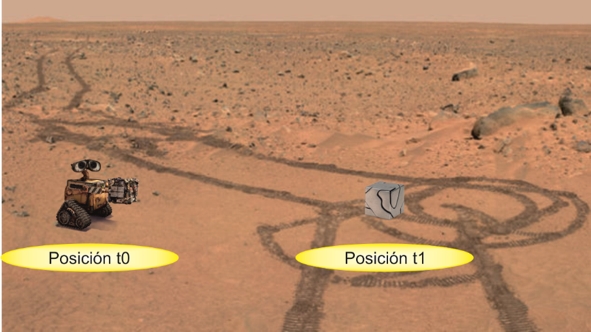
Por otra parte, también puede predecir su posición porque el GPS le indicaba su posición inicial y él mismo es el que ha dado la Orden de movimiento. Digamos que la Orden fue: las ruedas giran 10 veces. Por tanto, ahora predice que estará en Posición t0+10 vueltas de las ruedas. Pero aquí también hay un error, y es que en el mundo real hay ruido por todas partes, perturbaciones que no queremos ni predecimos; puede que las ruedas patinen con la arena y no hayan avanzado las 10 vueltas, o que hiciera mucho viento en contra y en vez de avanzar 5 metros ha avanzado 4.

Tenemos aquí un error de 1 metro, pero como el GPS tiene un margen de error de unos 3 metros, Wally “cree” que está en el lugar correcto. Peor aún, si ahora quiere desplazarse a por otra caquita metálica otros 5 metros y sigue los mismos pasos (recordemos que es una máquina, hace todo como previamente le hayamos indicado), ahora volverá a avanzar 4 metros en lugar de 5 que, sumados al error que cometió antes, son ya dos metros de diferencia, por lo que como basurero marciano tiene el futuro un poco negro.

Para lidiar con este problema se desarrollaron los filtros Kalman, que utilizan tanto la predicción como la medida del GPS para estimar con mucha mayor exactitud su posición real y lo mejor de todo, para estimar cuánto error ha cometido y poder modificar la Orden siguiente para no volver a cometerlo. En definitiva, para aprender. De este modo, va creando un modelo cada vez más acertado de cómo funcionan él y su entorno, se va adaptando.
Pero, ¿cómo funciona eso? ¿es necesaria una carrera en ingeniería, o dos, para comprenderlo? Pues veamos. Lo que hace es utilizar la predicción de la posición que hizo a priori, Posición t0+10 vueltas, y la compara con su posición real que mide el GPS a posteriori, Posición t1 real, y en función de esta diferencia ajusta una variable denominada ganancia Kalman, de modo que, si la diferencia es muy grande hay mucho error entre lo predicho y lo real, la ganancia será muy grande y a la Orden del siguiente movimiento le añadirá esta ganancia, en nuestro caso particular que las ruedas den más vueltas para así alcanzar los 5 metros. Si en el siguiente movimiento la diferencia entre la predicción y el GPS es muy pequeña, es decir, si apenas ha habido error, la ganancia Kalman disminuirá y la Orden enviada mantendrá su valor. No hay nada que corregir. Sencillo, ¿verdad?
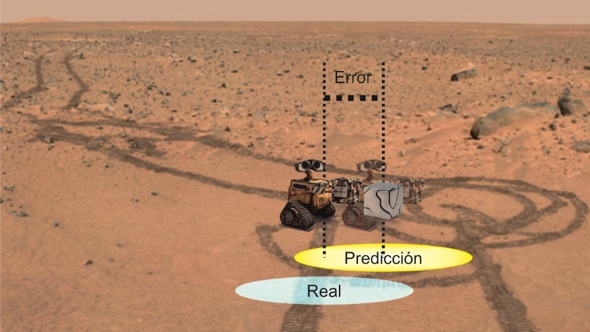
En resumen, para que una máquina pueda tener un movimiento autónomo y corregir su movimiento necesitamos:
- Un Actuador que ejecute algún movimiento, que es lo que vamos a controlar.
- Un Sensor, al menos, para tomar medidas de la posición.
- Una Orden que recibe este actuador para actuar.
- Una medida del Error
- Un algoritmo, un filtro Kalman, que permita al sistema aprender, pero que únicamente necesita los datos que recibe de los demás componentes.
A estas alturas los que hayan leído las dos entradas anteriores quizás ya sepan por dónde van los tiros. Ya hablamos de que, “Si conocemos nuestra posición actual, y poseemos una máquina de predecir el futuro, que la tenemos (aunque algunos parece que no), estamos preparados para iniciar los movimientos”, y también que, “Si la pierna se mueve como esperamos, como predice el cerebro…”
Pero cambiemos radicalmente de tercio, vamos a ver algunos resultados de diferentes experimentos reales. Ya hablamos de la corteza somatosensorial, que recibe información táctil y propioceptiva y, también, que cuando la corteza motora envía una Orden para movernos también envía una copia de esa Orden a la corteza somatosensorial y predice lo que deberíamos sentir cuando nos movemos. Pero, ¿cómo sabemos esto realmente?
Una aproximación consiste en entrenar a los macacos para que muevan un joystick con el que controlan un puntero en la pantalla del ordenador, el cual pueden llevar hasta un objetivo marcado en la pantalla. También podemos mover nosotros ese joystick artificialmente y sorprender al macaco. De esta forma tenemos dos tipos de movimientos en la mano del individuo: los movimientos activos, que el macaco decide realizar, y los movimientos pasivos, que mueven la mano del mismo modo pero el macaco no los espera.

Mientras hacemos eso, registramos la actividad de diferentes neuronas situadas en la corteza somatosensorial del macaco. Encontramos neuronas que hacen lo esperable ya que responden siempre que algo toca la mano del macaco, sea él mismo moviendo el joystick o seamos nosotros moviendo el joystick. Pero aquí viene lo bueno, por una parte, algunas de estas neuronas empiezan a responder ANTES de que el macaco empiece a mover la mano, es decir, estas neuronas predicen que algo va a tocar la mano. Pero, además, se encuentran neuronas más extrañas aún, algunas que únicamente responden cuando el movimiento es activo y otras que únicamente responden cuando el movimiento es pasivo. ¿Por qué? si en ambos casos la mano toca el joystick.
Las neuronas que únicamente responden a movimientos activos también son las que empiezan a responder ANTES de que ocurra el movimiento, lo que parece indicar que no responden a la sensación táctil de la mano que el movimiento causa en sí, sino que responden a la copia de la Orden que envía la corteza motora para iniciar el movimiento. Por su parte, las neuronas que únicamente responden a movimientos pasivos, a estímulos táctiles, deben poseer algún mecanismo que las impida responder durante el movimiento activo, cuando la mano también está siendo tocada. Esto parece indicar que esta Orden de la corteza motora inhibe a estas neuronas y, a su vez, las impide responder durante el movimiento activo. En cambio, cuando el movimiento es pasivo no hay ninguna Orden y las neuronas responden táctilmente.
Y ahora, con todo este cacao de neuronas y movimientos, ¿qué tenemos?
- Un Actuador: la mano y el brazo del macaco (o cualquier parte del cuerpo).
- Sensores que comunican la posición de la mano y el brazo. Las neuronas que responden táctilmente a cualquier movimiento de la mano, activo o pasivo.
- Una Orden que envía la corteza motora y llega también a la corteza somatosensorial, puesto que hay neuronas que únicamente se activan cuando el macaco quiere mover la mano e incluso antes de moverla, es decir, tenemos neuronas capaces de predecir el movimiento de la mano.
- Neuronas que detectan errores, que inhiben la respuesta sensorial cuando el movimiento es activo, pero cuando la información sensorial no es la predicha, cuando es un movimiento pasivo, sí responden, indicando un error en la predicción.
- ¿Un filtro Kalman? esto es lo que nos falta por saber. Aún no se han podido observar y medir las dinámicas de estas redes en conjunto, por lo que no podemos afirmar que este algoritmo se dé en la corteza somatosensorial.
Tenemos casi todos los ingredientes necesarios, pero nos falta alguno más como, por ejemplo, la ganancia Kalman. ¿Se observará en futuras investigaciones? Personalmente creo que aquí tiene mucho que decir el cerebelo, pero esa será otra historia…
Para finalizar, decir que esta es una de mis partes preferidas de la ciencia: comenzar con una pregunta simple, básica, a veces absurda incluso, como fue el querer saber por qué disminuye la respuesta sensorial del ratón mientras este corre, y acabar tirando del hilo hasta descubrir que, al parecer, este mismo mecanismo nos llevó a crear las precisas naves espaciales actuales. Por una parte, los ingenieros tenían que solucionar problemas de robótica, por el otro, los electrofisiólogos observaban sucesos extraños en el cerebro, ambos grupos sin una comunicación entre ellos, pero manejando, posiblemente, el mismo fenómeno. Y lo que es mejor aún, este conocimiento nos permite en la actualidad combinar y utilizar esta información para nuestro propio beneficio, como por ejemplo…
Si los dioses te impiden ver este magnífico y espectacular vídeo, avanza al menos hasta el minuto 15.
Información adicional y bibliografía:
- Vídeos (en inglés) donde se explica el funcionamiento del filtro Kalman y cómo implementarlo en cualquier dispositivo electrónico (¿o biónico?) para poder usarlo como uno quiera:
- Artículo (gratuito) donde registran neuronas en macacos: http://jn.physiology.org/cgi/pmidlookup?view=long&pmid=23274308
- Entrada de la Wikipedia (en inglés) con bastante información sobre filtros Kalman: https://en.wikipedia.org/wiki/Kalman_filter